Merkle trees are incredibly valuable when it comes to blockchains. In distributed systems, Merkle trees help with easy verification of information without flooding the network with unnecessary data. If you look at the timeline, the first-ever mention of the Merkle Tree was in the early 80s when the computer scientist Ralph Merkle, renowned for public-key cryptography introduced Merkle Tree for verifying data integrity in a peer-to-peer network. He then introduced the concept of hashing, as a new mode of verification conduct.
The aim of this article is to help beginners in comprehending the idea of the Merkle tree when it comes to the representation of data and also elite on different operations performed on it. With no further adieu, let’s check it out.
“TREE”
What comes to your mind when you think of a TREE? A physical object decored with luscious green leaves, branches, a huge trunk and a strong firming root. However, in computer science vernacular, “Tree” has a different meaning. Here it refers to a data structure, resembling an “inverted” tree.
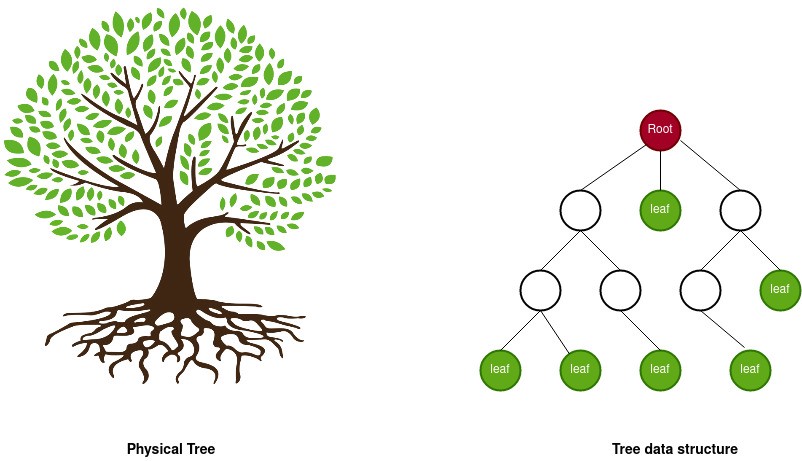
Tree as Data Structure
The inverted tree structure adorns representing the hierarchical relationships among data. Let us see an example for hierarchical data: a set of four files organized in a folder hierarchy.
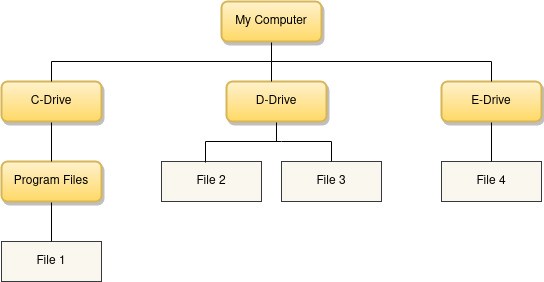
Now let’s glide through some terms related to tree data structure based on the illustrated example.
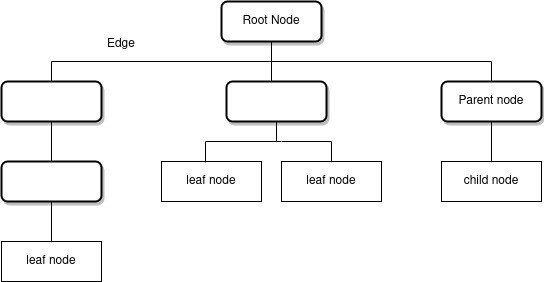
- Each member of the tree is called a node. The lines connecting the nodes are called edges.
- The topmost node is called the root node. Every operation on the tree begins from the root node.
- Parent nodes comprise one or more child nodes.
- The bottom nodes of the tree are called leaf nodes.
- The process of navigating a tree is called traversal.
- A path between two nodes consists of the nodes which are visited while moving through the branches that connect those two nodes.
Do you know the tree data structure allows faster search operations making information retrieval easy?
More so, one can find different models of tree data structures. A tree whose node elements have at most 2 children is called a Binary Tree. Merkle Tree is a special variant of Binary Tree with different attributes.
Now that you got a firm idea of tree data structures, let’s check out the Merkle Tree in detail. However, before that let’s have a quick stroll through the concept of Hashing.
Hashing is the process of converting data to a unique fixed-size string called a hash value made up of a combination of numbers and alphabets. The memory space of a hash value will be lower than the memory space of the data represented by it. There are various functions available for hashing. A common example is the Secure Hash Function (SHA-256).
Do you know Hash functions have some interesting properties?
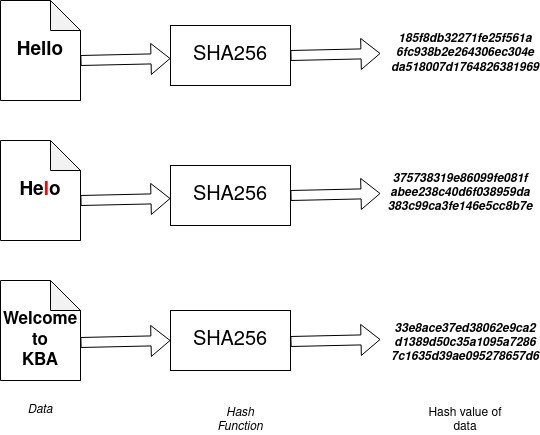
If you look at the above illustration, you can see that we tried hashing three input values. You can see that though the size of inputs is different, the size of the hash value always remains the same. However, a small change in the input value (a missing ‘l’) generates a completely different hash value. Also, the hash functions are irreversible, given a hash value, one cannot find the input data.
Merkle Tree
In a Merkle tree, every node is labelled by the hash value of the data it represents. Let us assume that we have a set of data, a list of blockchain networks: Bitcoin, Ethereum, Litecoin, Monero, Hyperledger, Corda, Multichain. The Merkle tree will look like below:
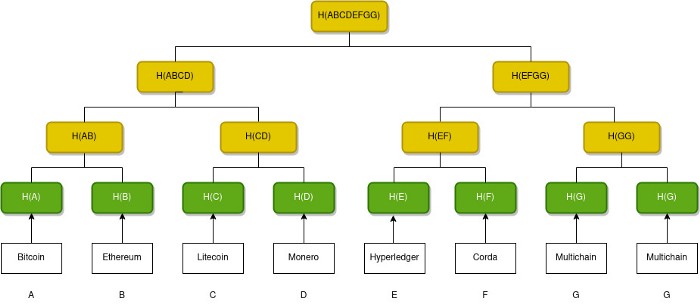
Let us now see how the Merkle tree is constructed.
- Find the hash value of every data item. These hash values will be the leaf nodes of our Merkle Tree.
- Group the leaf nodes into pairs, starting from left to right.
- Create a parent node for each pair. Combine the hash values of the leaf nodes and apply the hash function to the combined value. This will be the label of the parent node.
- Next group the parent nodes into pairs and repeat the above step.
- Continue the pairing until we are left with a single node which is the Merkle root or root hash.
Now you may have a question in mind. What if we need to pair an odd number of nodes?
Well…, we have got you covered.
Just create a duplicate of the last node. We now have an even number of nodes in the Merkle Tree. In the above example, the last element is duplicated.
Merkle root is a representative of the Merkle tree. It acts as a digital fingerprint of the data set represented by the tree. Remember that even a slight change in the data will change the hash value of the leaf and this will change the hash values of all the nodes connecting that leaf node to the root node, eventually resulting change in the root hash.
Searching in a Merkle Tree
The major use of the Merkle tree is that it makes search operation faster and efficient. One can easily check whether a particular data item is represented in the tree, without traversing the entire tree. This is also called Proof of Inclusion.
Consider the previous example. Suppose we need to check whether Hyperledger is included in the list. The only data we have is the root hash H(ABCDEFGG) and H(E), the hash value of “Hyperledger”. We can re-calculate the value of root hash from H(E) by tracing the path from H(E) to the root node. Remember visiting a node requires a calculation of the hash value represented by that node. For that, we need some additional information.
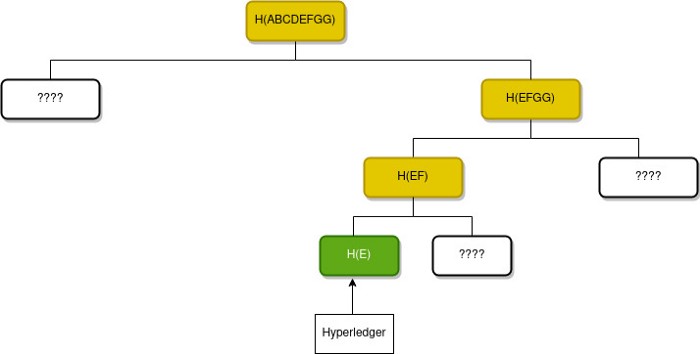
Here three values are missing to calculate the root hash. If one can get the missing values as input, then it becomes easy to calculate the root hash as shown below.
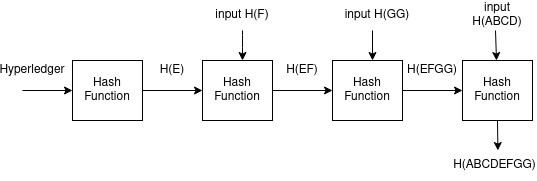
If you see that the re-calculated value of root is equal to the true root hash, it means that Hyperledger is included in the list. If there is a mismatch, it denotes that Hyperledger is not included in the list.
A Merkle path for a leaf in a Merkle tree is the smallest number of additional nodes in the tree required to compute the root hash. In our example, we required 3 additional nodes to calculate the root hash. So the Merkle path for H(E) is H(F), H(GG), H(ABCD). We can prove that a data item is included in a Merkle tree by producing a Merkle path. If the root hash calculated using the Merkle path is the same as the true root hash, it simply denotes the leaf node is present in the tree.
Why Merkle tree?
Merkle trees are efficient data structures in terms of storage and time. They store hash values of data that require lesser storage space. One can easily search for data by producing the Merkle path, rather than searching the entire tree. The efficiency of the Merkle tree also depends upon the selection of hash functions.
You may note that Merkle trees are used in various distributed applications where data is replicated and stored by multiple parties in a network. If anyone tries to alter data at one location, the hash values will change, leading to a change in the root hash. Thus others in the network can detect this based on the mismatch in the root hash.
Hope you enjoyed reading our article. Stay tuned to PART-2 for more explicit pieces of information.

