
Blockchain has the potential to do many things, however to achieve these things one thing is vital- Programmability. Ethereum is a programmable blockchain that lets you do many things making it truly transformational. It runs down a wide variety of applications meeting different industry needs and purposes. This is the reason that Ethereum accounts and transactions have too many associated properties which need to be efficiently represented.
If you ask for Ethereum’s key data structure, there is one and only answer- Merkle Patricia Trie. Ethereum uses the data structure that combines the power of Merkle tree and Patricia trie. The Merkle Patricia trie is used for representing certain data in the header of an Ethereum block.
We have already discussed Merkle tree and Patricia trie. To brief, Merkle tree has pivotal role in management of blockchain network as it uses the hash representation to save storage space and speed up search operations. While, Patricia trie is a tree-like data structure used to store (key, value) pairs. The compression technique in the Patricia trie reduces the storage requirement in the blockchain.
In Ethereum, each node of the tree is referenced by its hash value, like a Merkle tree. The root hash acts as a digital fingerprint of the entire data set represented by it. If any key-value is updated, the Merkle root will also change. Ethereum keys are represented in a hexadecimal format, which has 16 possible characters ( 0–9 and A-F).
Merkle Patricia trie comprises 4 types of nodes:
- null: A non-existent node, represented as an empty string.
- branch: A node that has links to a maximum of 16 distinct child notes, corresponding to 16 hex characters. It has also a value field.
- leaf: An “end-node” that contains the final part of the key and a value.
- extension: A “shortcut” node that stores a part of the key based on a common prefix, and a link to the next node.
-Usually trie is stored in a separate database. The “link” fields in a node stores the hash value of the next node. This hash value is used as a key to retrieve the actual node from the database during traversal. Therefore searching a key in the trie requires multiple database lookups for getting the nodes in the path.
-Leaf nodes and extension nodes have similar structure. So a flag is included at the beginning of path value to differentiate between them.
Tries in Ethereum
Ethereum uses three trie structures. You might be wondering why multiple tries. Well, it is that we have to deal with permanent data like transactions in a committed block as well as temporary data like account balance which gets updated. Data structures are demanded to store them separately. In Ethereum, every block header stores roots of three trie structures: stateRoot, transactionRoot, and receiptsRoot.
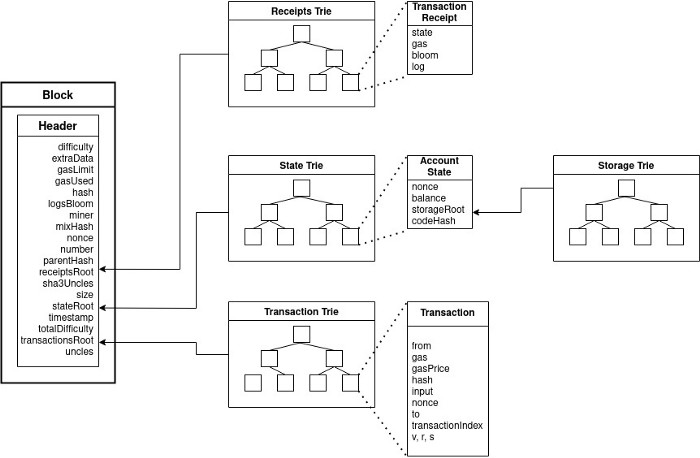
State trie: The state trie / world state trie represents a mapping between account addresses and the account states. The account state includes the balance, nonce, codeHash, and storageRoot. The storageRoot itself is the root of an account storage trie, which stores the contract data associated with an account. Here the key is a 160 bit address of an Ethereum account and the value is the account state. The root node depends on all internal data and its hash value acts as a unique identifier for the entire system state.
Ethereum accounts are added to the state trie only after a successful transaction is recorded against that account. The world state trie stores some temporary data which gets updated, changing the root hash frequently. The stateRoot is hash of the root node of the state trie, after every transactions are executed and committed.
Transaction trie: It is created on the list of transactions within a block. The path to a specific transaction in the transaction trie is tracked based on the position of the transaction within the block. Once mined, the position of a transaction in a block does not change. So a transaction trie never gets updated. This is similar to the Merkle tree representation of transactions in Bitcoin and the transaction verification can be done similarly. The transactionRoot is the hash of the root node of the transaction trie.
Receipt trie: The receipt records the result of the transaction which is executed successfully. It consists of four items: status code of the transaction, cumulative gas used, transaction logs, Bloom filter (a data structure to quickly find logs). Here the key is an index of transactions in the block and the value is the transaction receipt. Like transaction trie, receipt trie never gets updated. The receiptsRoot is the hash of the root node of the trie structure populated with the receipts of each transaction in the transactions list portion of the block;
-The “value” represented by tries often consists of multiple data items. For example account state consists of 4 data items. So an encoding technique is used to convert them into a uniform format that can be stored or transmitted across a network. Ethereum uses Recursive Length Prefix (RLP) encoding for data structures such as accounts, transactions and blocks. The values represented in tries will be the RLP encoding of the actual values. The decoding procedure is applied whenever the value is retrieved.
-The root values in the block header stores the hash value of the root node of the corresponding trie. Ethereum uses Keccak hash function.
-Block headers store only the trie roots. Ethereum clients store the tries in databases like LevelDB or RocksDB. To retrieve a node from the database, the hash value of node is used as a key.
Below is an example of a block header

Transaction Example:
Transaction Receipt Example:
Account Example

Let us see a simple Merkle-Patricia Trie example used for storing the mapping between account address and ether balance.
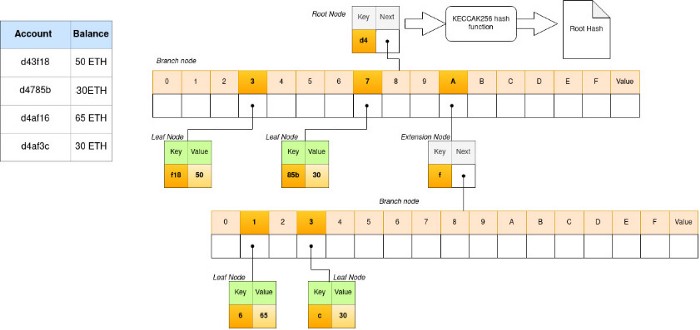
Let us see a simple Merkle-Patricia Trie example used for storing the mapping between account address and ether balance.

Since the nodes are stored in the database, each node visit will require a database lookup.
Why Merkle Patricia trie ?
We already saw how Merkle Patricia trie combines the advantages of Merkle and Patricia trie. Now let us look into some of the benefits offered by Merkle Patricia trie.
In case of state trie, it allows quick re-calculation of root hash when updates like changes in account balance, nonce, etc takes place. The root value entirely depends on data. It does not depend on the order in which updates are made. So even if updates are done in different order, the final tree will remain the same.
Hashing helps with easy detection of data changes . If any peer attempts to make alterations to the data, the root hash will change notifying other peers in the network to identify the change.
Querying is easy without requiring re-computation of the whole trie.
Check whether transaction is included in a block ?. Ask transaction trie.
Want to check whether an account is valid ?. Ask state trie
Want to know your account balance ? Ask receipt trie
Devices with limited storage and computation capability( light weight clients) like mobile applications can make use of this feature for data verification.
The tries are stored in a database. So we can prove that a large amount of data is correct, without storing the whole data in the blockchain. It reduces the storage overhead of blockchain also.
Merkle Vs Merkle-Patricia
Since we have seen both Merkle tree and Merkle Patricia tree, let us analyze some of the major differences that keeps them separate.
1. Root of a Merkle Patricia trie does not depend on the order of data. However, Merkle root depends on order of data, since we are pairing adjacent nodes and taking the hash value.
2. Tree size of Merkle Patricia trie is lower than a standard Merkle tree due to prefix based compression techniques.
3. Merkle patricia tries are faster than Merkle trees, but the implementation is complicated.
References
https://eth.wiki/fundamentals/patricia-tree https://blog.ethereum.org/2015/11/15/merkling-in-ethereum/
https://medium.com/shyft-network-media/understanding-trie-databases-in-ethereum-9f03d2c3325d https://ethereum-classic-guide.readthedocs.io/en/latest/index.html
https://eth.wiki/json-rpc/API https://ethereum.github.io/yellowpaper/paper.pdf

